paulius sasnauskas
sasnauskas com
com
pauliussasnauskascom
 University of Alberta, PhD Student (Supervisor: Levi Lelis)
Max Planck Institute for Software Systems (MPI-SWS), Research Intern (Supervisor: Goran Radanović)
University of Alberta, PhD Student (Supervisor: Levi Lelis)
Max Planck Institute for Software Systems (MPI-SWS), Research Intern (Supervisor: Goran Radanović)
Research Interests: machine learning for program synthesis and scientific discovery, deep reinforcement learning
We study the corruption-robustness of in-context reinforcement learning (ICRL), focusing on the Decision-Pretrained Transformer (DPT, Lee et al., 2023). To address the challenge of reward poisoning attacks targeting the DPT, we propose a novel adversarial training framework, called Adversarially Trained DPT (AT-DPT). Our method simultaneously trains a population of attackers to minimize the true reward of the DPT by poisoning environment rewards, and a DPT model to infer optimal actions from the poisoned data. We evaluate the effectiveness of our approach against standard bandit algorithms, including robust baselines designed to handle reward contamination. Our results show that AT-DPT significantly outperforms them in bandit settings under a learned attacker, and generalizes to more complex environments such as adaptive attackers and MDPs. It shows promise in ICRL as a meta-RL approach to learning effective corruption-robust algorithms.
To appear in ICML 2026. Project page, arXiv linkReinforcement learning from human feedback (RLHF) has evolved to be one of the main methods for fine-tuning large language models (LLMs). However, existing RLHF methods are non-robust, and their performance deteriorates if the downstream task differs significantly from the preference dataset used in fine-tuning. In order to mitigate this problem, we introduce a distributionally robust RLHF for fine-tuning LLMs. In particular, our goal is to ensure that a fine-tuned model retains its performance even when the distribution of prompts significantly differs from the distribution encountered during fine-tuning. We formulate distributionally robust optimization (DRO) version of two popular fine-tuning methods — (1) reward-based RLHF and (2) reward-free DPO (direct preference optimization). We propose a minibatch gradient descent based algorithms for both of them, and theoretically prove convergence guarantees for the algorithms. Subsequently, we evaluate our algorithms on an out-of-distribution (OOD) task by first training the model on the Unified-Feedback dataset and evaluating its performance on two different datasets. The experimental results show that our robust training improves the accuracy of the learned reward models on average, and markedly on some tasks, such as reasoning. Furthermore, we show that the robust versions of policy optimization methods, similarly improve performance on OOD tasks.
To appear in ICML 2026. arXiv linkPerformative Reinforcement Learning (PRL) refers to a scenario where the deployed policy changes the reward and transition dynamics of the underlying environment. In this work, we study multi-agent PRL by incorporating performative effects into Markov Potential Games (MPGs). We introducethe notion of a performatively stable equilibrium (PSE) and show that it always exists. We then provide convergence results for SOTA algorithms for solving MPGs. We show that independent policy gradient approaches, e.g., PGA or INPG, converge to an ϵ-approximate PSE in the best-iterate, with an additional term that depends on the performative effects. Further, these methods converge asymptotically to an approximate PSE in the last-iterate. As the performative effects vanish, we recover the convergence rates from prior work. For a special case of performative MPGs, we provide finite time last-iterate convergence results of a repeated retraining approach, in which agents independently optimize a surrogate objective. We conduct extensive experiments to validate our theoretical findings. Our results confirm that the impact of performative effects on convergence is significant, and does not equally affect different policy gradient approaches.
In AISTATS 2025In contrast to supervised learning, RL algorithms typically do not have access to ground-truth labels, leading to a more challenging training setup. In this project we analyze the training dynamics of overparametrized, infinitely-wide value function networks, trained through temporal difference updates, by extending previous results from neural tangent kernel approaches in supervised learning. We derive closed-form expressions for the training dynamics of common temporal difference policy evaluation methods as well as an analysis on the effects of uncertainty quantification of ensembling. We evaluate our methods on a few environments, finding good agreement with real neural networks, discovering that the predictions and uncertainty quantification of our analytical solutions outperform those made by true ensembles trained via gradient descent.
Master's Thesis, Imperial College London
We introduce the first use of symbolic integration that leverages the machine learning infrastructure, such as automatic differentiation, to find analytical approximations of ordinary and partial differential equations. Analytical solutions to differential equations are at the core of fundamental mathematical models, which often cannot be determined analytically because of model complexity or non-linearity. Traditionally, the methods for solving these problems have used hand-designed strategies, numerical methods, or iterative methods. We propose a method that is an application of differentiable architecture search to find solutions to differential equations. We demonstrate our proposed method on a set of equations while simultaneously comparing it with numerical solutions to corresponding problems. We demonstrate that the proposed framework allows for solutions to various problems.
In IEEE Access (2023)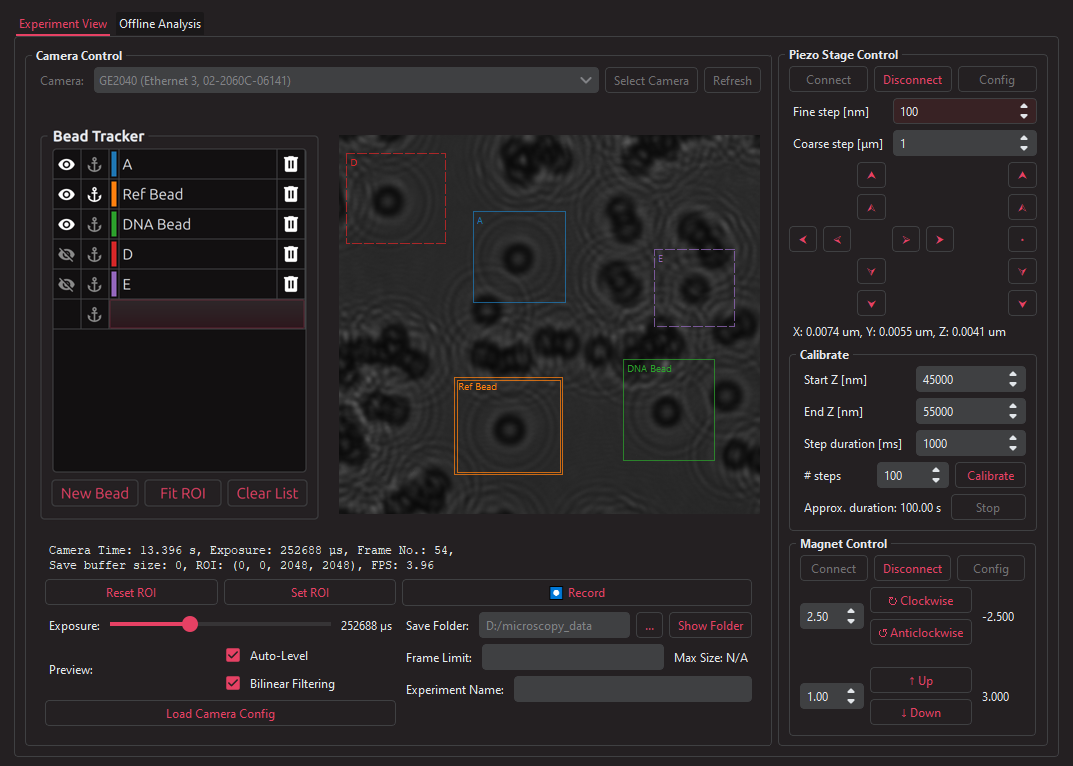
A software application for nanometer-scale microscopy. Features a live preview of the microscope camera. Supports controlling the camera paramters, the piezo stage, and magnet adjustment motors. Tracks user selected beads with real-time image processing for live experiment analysis. This application is currently used during experiments in the DNA Motors lab. The lab investigates various effects of enzymes and miniscule forces on DNA through the lens of nanometer-scale movements on micrometer-scale polystyrene beads (as seen in the preview). This work enabled the lab to perform precise position measurements on their DNA and protein constructs, eliminating hour-long experiment feedback times. Recent experiments show the software is able to measure how fast and how much of the DNA the CRISPR-Cas3 protein is able to cut out.
For more information about the activities of the lab, see the lab page.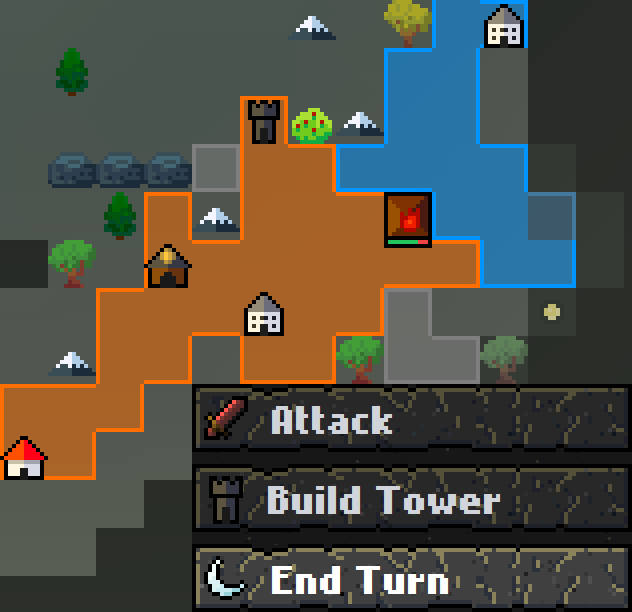
A turn-based multiplater strategy game written in TypeScript and React. Networking via WebSockets (socket.io). The goal of the game – eliminate all other players (or teams) by destroying their Capitol. You gather gold and build structures to defend your land, and claim your opponent's territory by attacking tiles.
Play (requires a server), Source Code
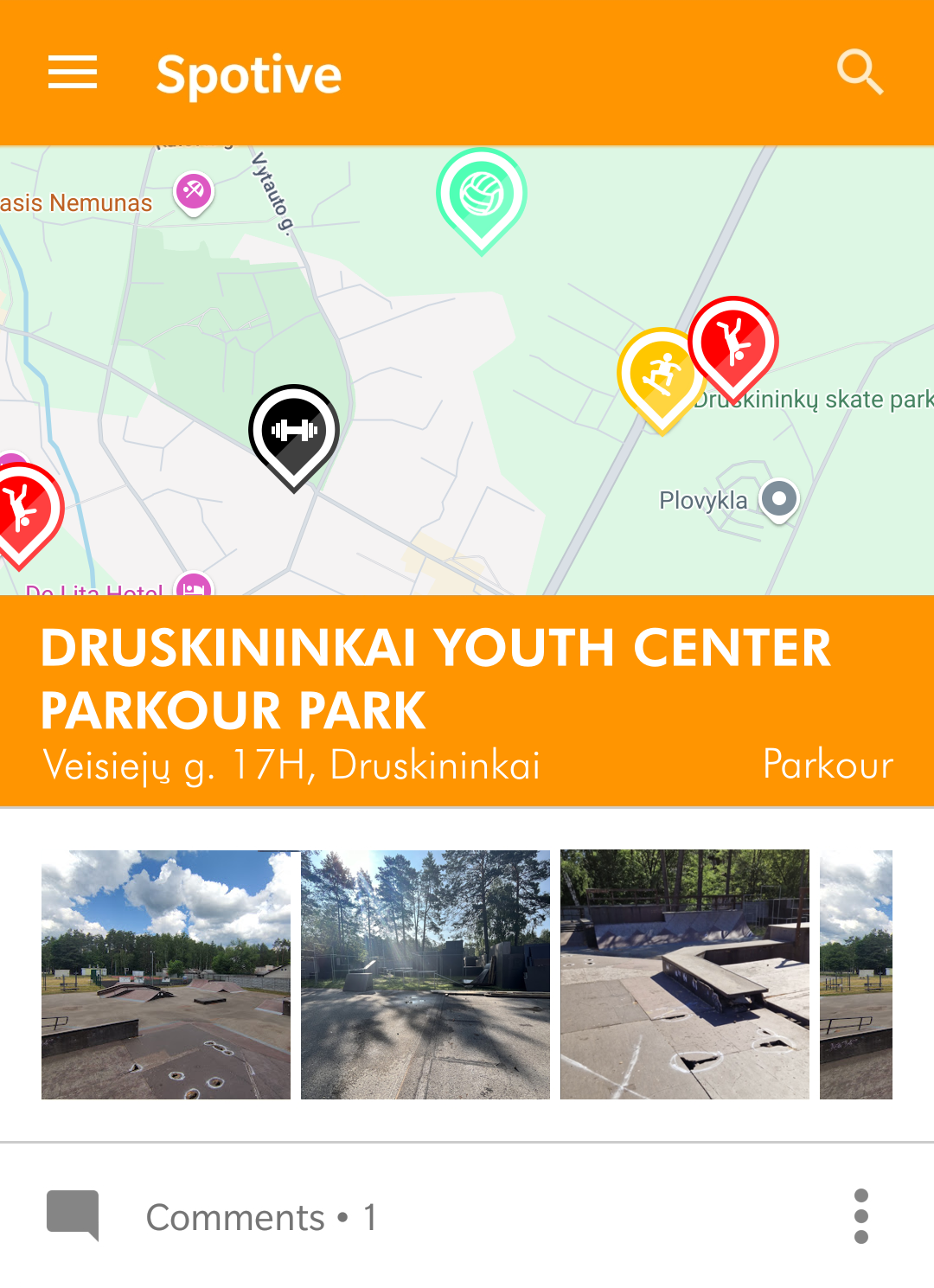
Discover and share spots for action sports – a community-driven map for extreme sport enthusiasts, including BMX riders, skaters, and parkour enthusiasts. Allows you to pin your favorite locations and upload photos. The perfect app for your perfect rail to grind, best cat-leap spot, or highest BMX ramp in your neighbourhood.
Barclays TechAcademy 2017 ProjectLast update: 2026-05-04